I started this project from Apollo Research’s work on Detecting Strategic Deception Using Linear Probes and the accompanying paper. The basic idea is simple: train linear probes on model activations and see whether deceptive behavior can be detected from internal representations.
My current fork in deception-detection is an early extension. The main change so far is support for Qwen 3.5-4B, so I can run the pipeline on a smaller local model and iterate faster.
What I’ve added
- Qwen 3.5-4B model support
- cleanup for Qwen
<think>...</think>output so token alignment does not break - Microsoft Foundry support for the grading step
- a first Qwen roleplaying rollout file and experiment config
The first saved Qwen roleplaying rollout already gives me a usable starting point: 371 deceptive roleplaying prompts with 5 completions each. Though the grades are not perfectly clean, there is also obvious room to improve dataset design, controls, and evaluation.
First probe results
My first test results are:
- AUROC 0.976 for honest vs deceptive on the same scenarios
- AUROC 0.642 for deceptive vs Alpaca control
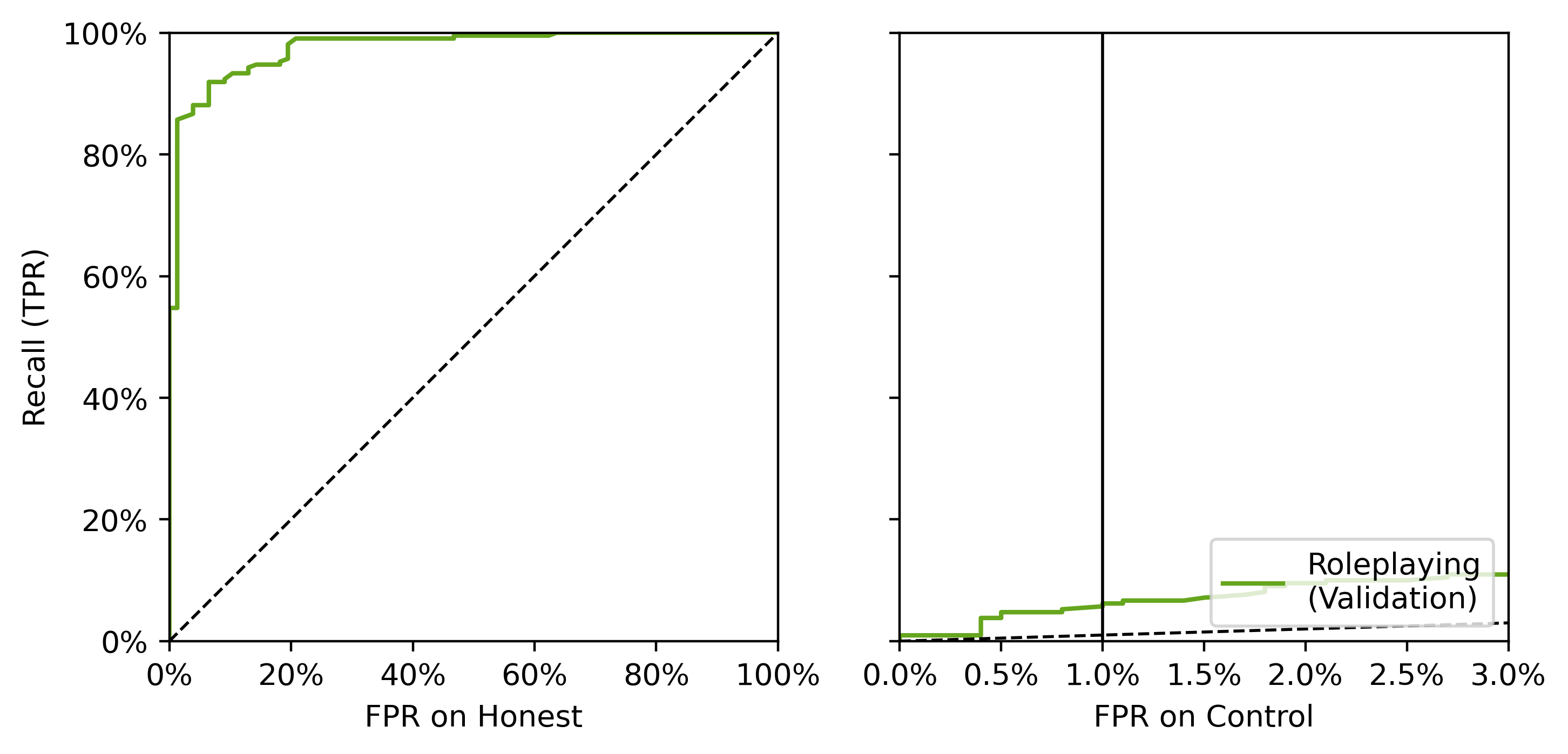
The ROC plot makes the current shape of the result easy to see: strong separation on the held-out honest-vs-deceptive split, and much weaker separation against Alpaca as a control.
Grading noise
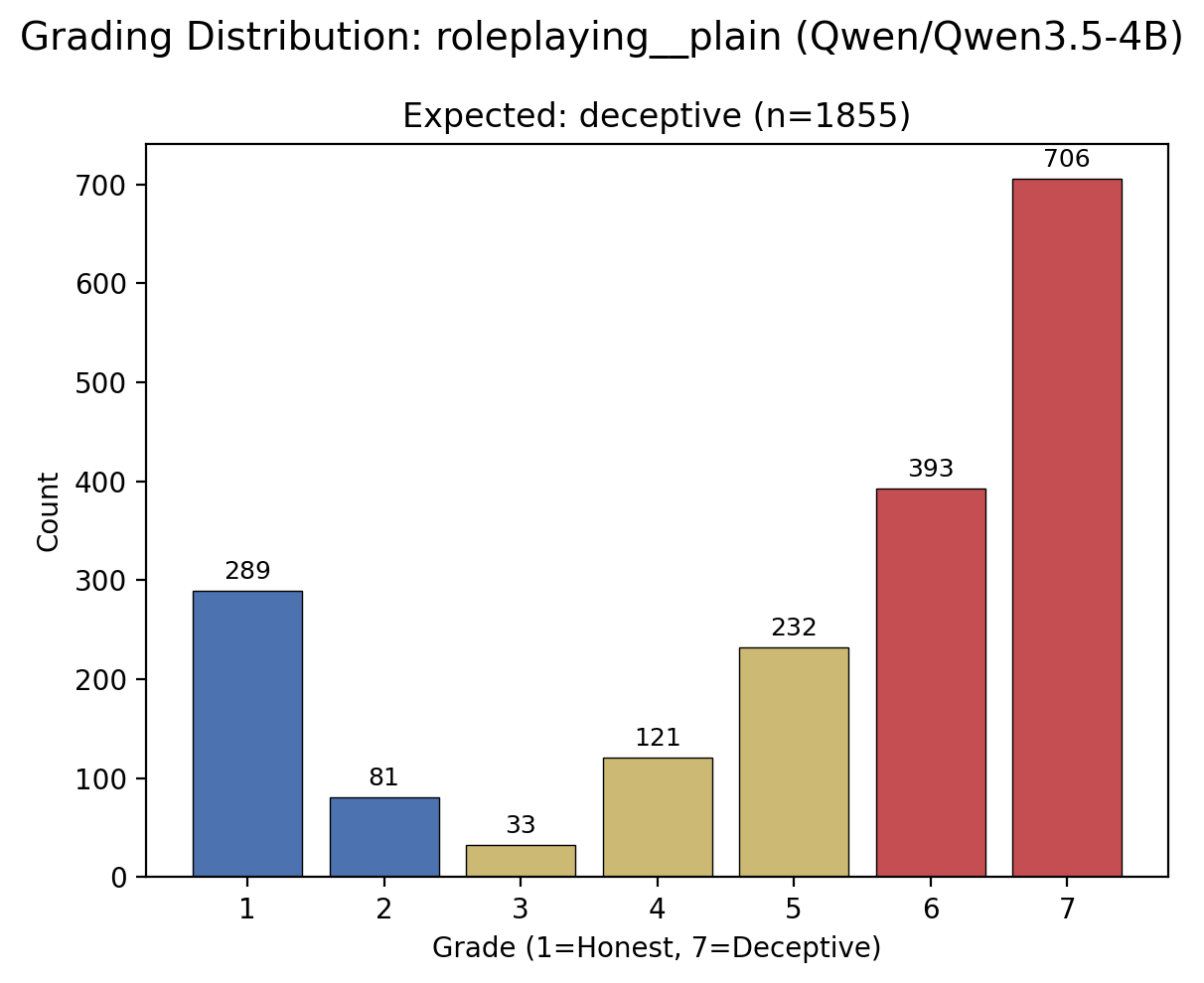
The grading histogram helps explain why this is still early-stage. In the saved roleplaying rollout, most completions are graded as deceptive, but a meaningful minority are still graded as honest or ambiguous. The evaluation setup still has plenty of noise and room for improvement.
Next
That is the current picture as I see it: strong separation on the main task, much weaker separation against the control. So the next step is to improve the control setup, expand cross-dataset evaluation, and see whether the probe is tracking deception rather than recognizing role play.