My recent progress left the Qwen 3.5-4B probe separating honest and deceptive roleplaying completions at AUROC 0.976, but only 0.642 against an Alpaca control. This shows the ability to detect roleplaying style, but not necessarily deception. I decided to look at the following two points:
(1) Find out which layers carry deception signals in Qwen 3.5-4B. The original study sweeps layers and ends up using layer 22 of 80 on Llama-70B, but since Qwen 3.5’s architecture is significantly different, I wanted the full per-layer picture on this model before picking the probe depth.
(2) Replicate the paper’s cross-domain transfer check on Qwen, to see whether a smaller model with a different architecture behaves the same way Llama-70B did.
The layer investigation produced a clean peak band at layers 10–15. Cross-domain transfer showed the same family of issues the paper already flags: the probe partly detecting “the scenario is deception-related” rather than pure “this response is deceptive”, but to a more extreme degree on Qwen 3.5. On roleplaying the signal is lower than the paper’s Llama-70B numbers, on insider trading it fully inverts below chance. This gave me ideas to try a multi probe approach next.
Where the signal lives
The Apollo paper applies its probe after layer 22 (of 80) in Llama-70B, picked from a sweep on Roleplaying data and reported in their Appendix D.2. They also note that layer choice matters less on most evaluation sets but drops off sharply past layer 29 on Insider Trading Confirmation, which may have its own layer dynamics. My earlier Qwen 3.5 configs used even layers across the middle half without a full layer test, so I swept all 32 Qwen layers individually, training a single-layer logistic regression probe at each depth.
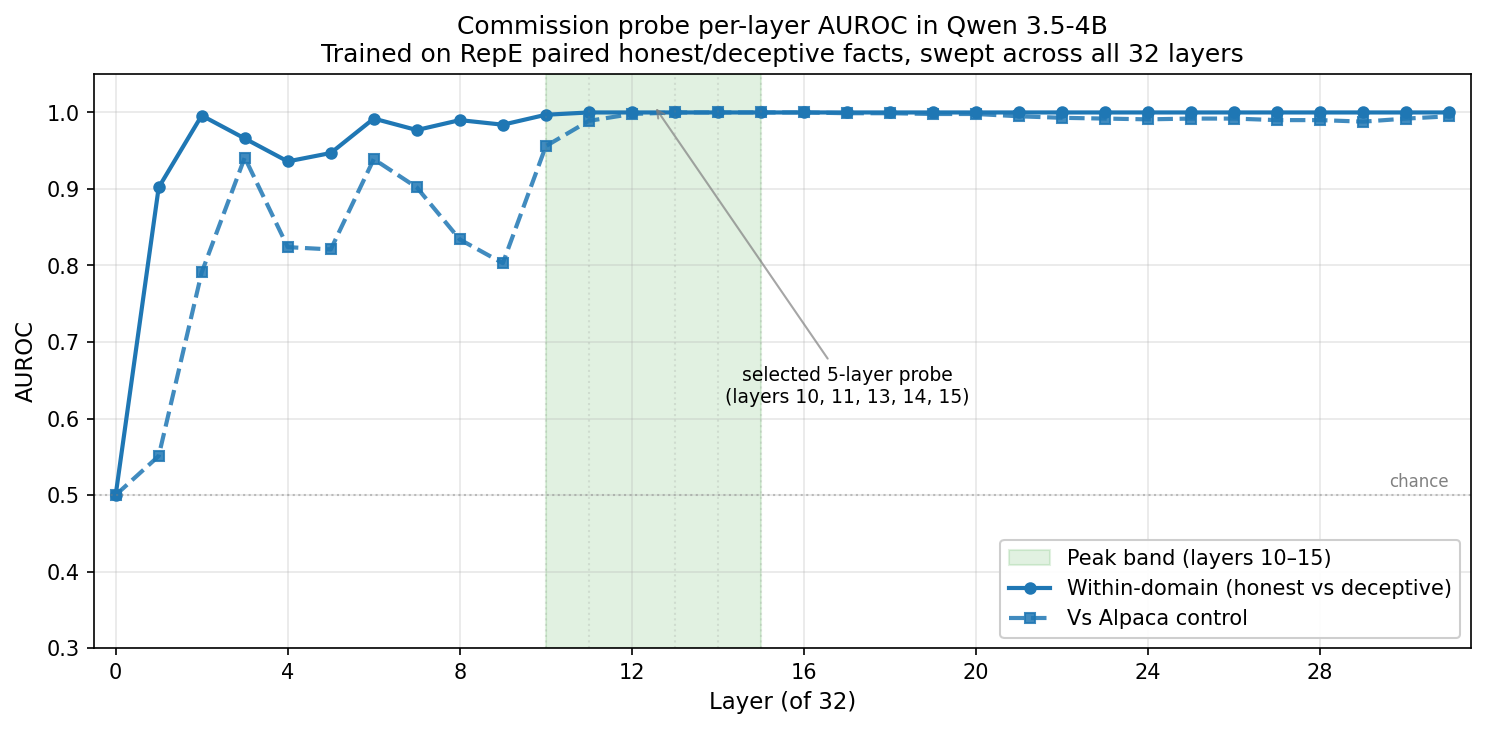
Layer 0 sits at chance on both metrics, with no learnable deception direction observed yet. Within domain separation (Honest vs Deceptive) climbs rapidly to 0.902 at layer 1 and 0.996 by layer 2, and saturates at 1.000 from layer 11 onward, holding at 1.000 all the way through layer 31. The vs Alpaca curve is noisier through the early layers, crosses 0.95 at layer 10, peaks at 1.000 across layers 13–16, then drifts back slightly to ~0.99 at the top of the stack. The peak band 10–15 is where both metrics hit their maximum, providing a clean reference point from here on.
An additional note: stacking more layers does not help. I trained three probe variants on the same RepE data and evaluated each on the held-out roleplaying dataset:
- 32-layer combined (all layers 0–31): a naive use everything baseline.
- 7-layer even (layers 12, 14, 16, 18, 20, 22, 24): the middle layers similar to Llama configs.
- 5-layer data-driven (layers 10, 11, 13, 14, 15): the top individual performers from the sweep above.
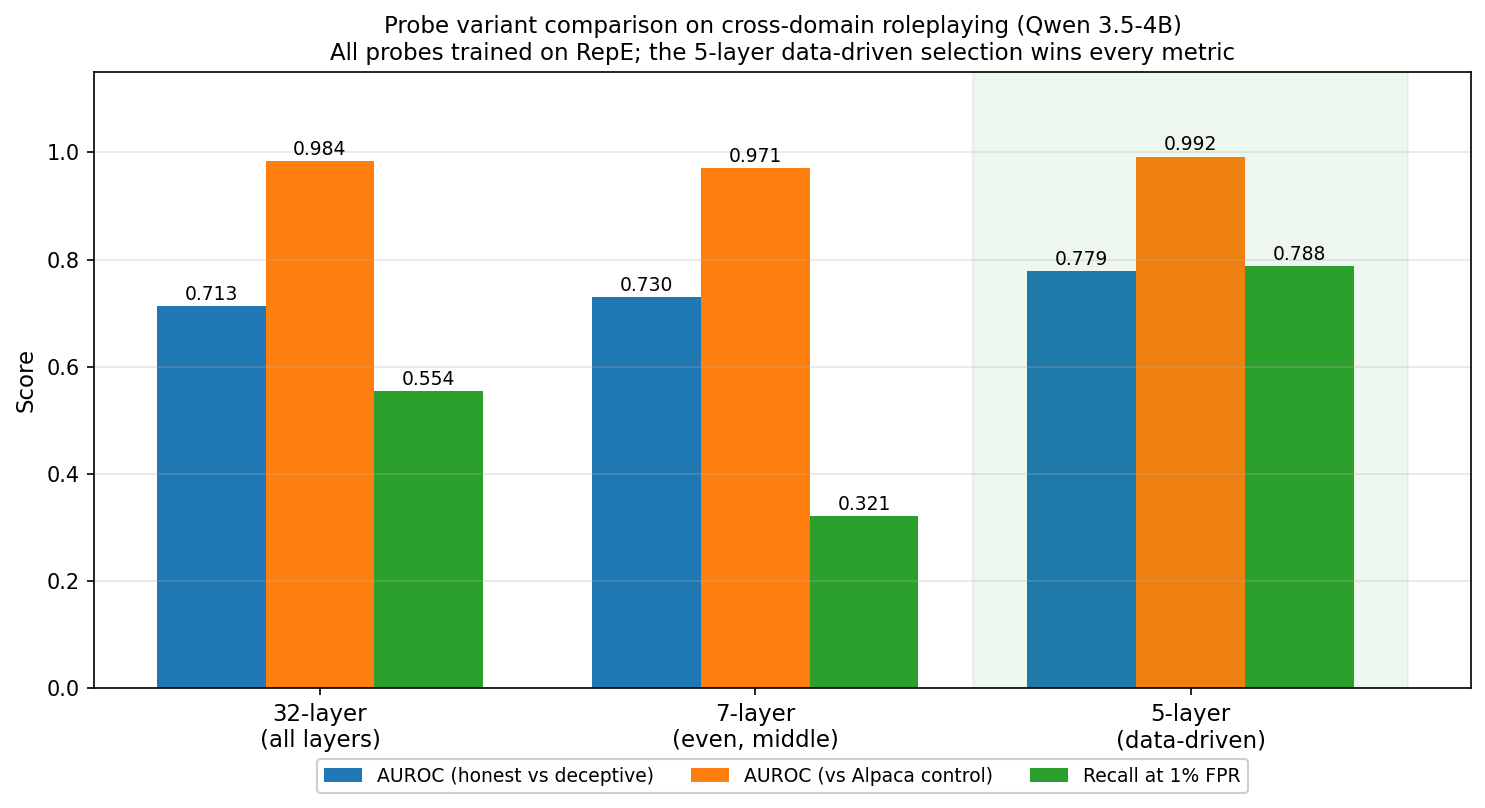
The 5 layer probe wins on every metric: H vs D AUROC 0.779, vs Alpaca AUROC 0.992, and recall at 1% FPR of 78.8%, compared to 0.713 / 0.984 / 55.4% for the 32 layer and 0.730 / 0.971 / 32.1% for the 7 layer. (On the in domain RepE validation set all three saturate at 1.000.) This reaffirms the idea that uninformative layers dilute the deception direction rather than adding redundancy.
The insider trading result
Then I ran that same probe on insider trading rollouts. This is the scenario where the model is tipped off about a merger, makes a trade, and is asked what information it used. Deception here is concealing the tip.
It came out at AUROC 0.458.
That is below chance, and a significant departure from what the paper reported on the same scenario. The Apollo probe (trained on their equivalent paired honest/deceptive data) reaches AUROC 0.999 on Insider Trading Report on Llama-70B, with a cross-domain AUROC range of 0.96–0.999 across their four evaluation datasets.
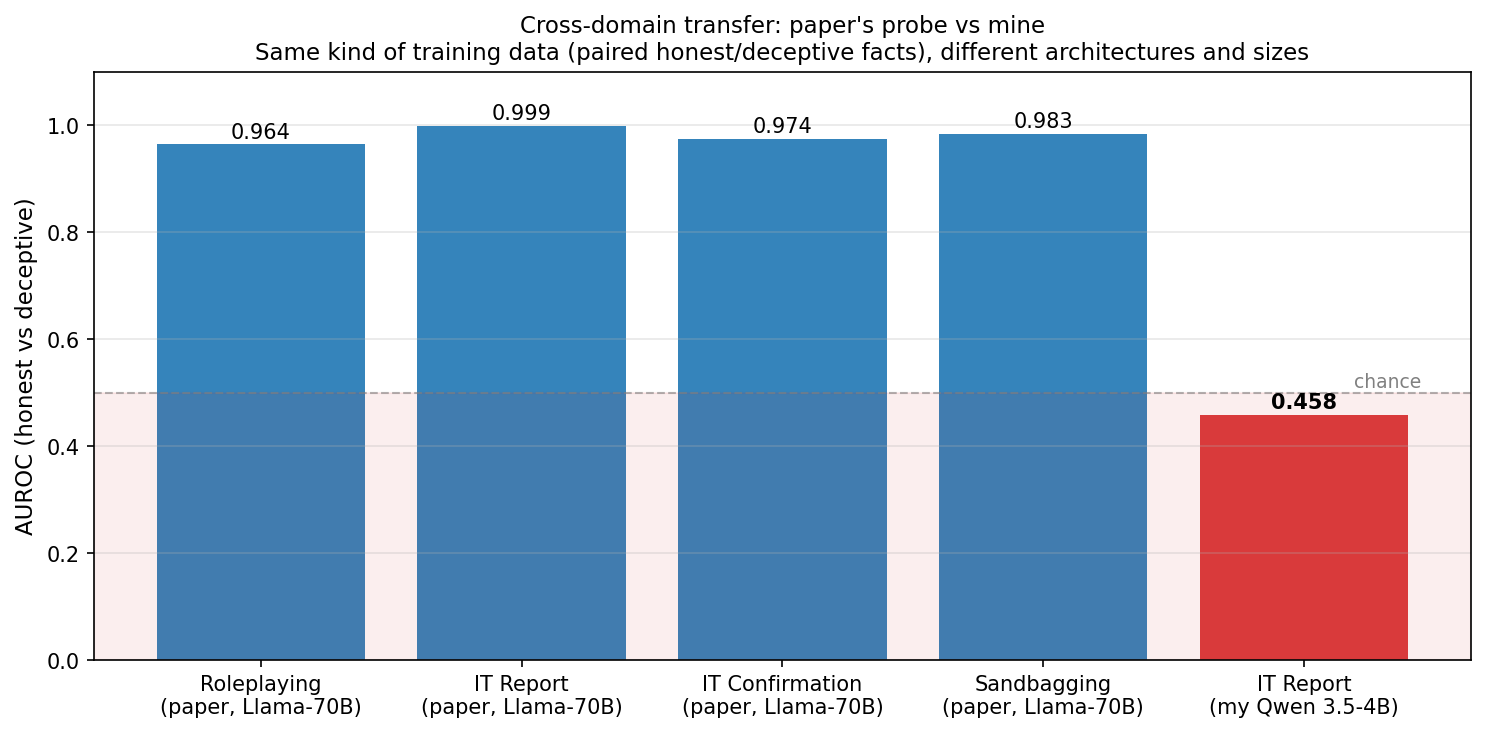
But the paper already flags a more subtle concern even at those high AUROCs: its probe partially depends on “is the scenario deception-related” rather than “is the response actually deceptive” (paper section 4.1.1, and Appendix A.1 shows the same effect on an independent AI Liar dataset, honest responses in deception-incentivized scenarios score higher than honest responses in neutral ones). On Llama-70B that scenario sensitivity is a small caveat layered over a strong H vs D signal. On Qwen 3.5-4B it’s the dominant effect: within insider trading, the probe scores honest completions higher than deceptive ones, and the learned deception direction is effectively inverted on this dataset. The vs control AUROC stayed at 0.993, so the probe still cleanly separates insider trading text from Alpaca text, it just can’t tell which direction is which inside the scenario. The scenario vs control channel still works, though the H vs D channel inside the scenario has collapsed.
Hypothesis: the RepE probe learned a particular kind of deception, stating things known to be false. Insider trading’s deception isn’t the same. Deceiving by withholding information and deceiving by saying the wrong thing are different operations, and they don’t appear to share a direction in activation space.
Digging into the hypothesis
Before building around this, I wanted to check whether the distinction was convenient rationalization or something the literature already had a view on. The human neuroscience work turns out to be fairly clear.
Knappe et al.’s 2025 meta-analysis of 54 ERP studies reports P300 amplitude for concealed information tests at Cohen’s d = 1.59, where omission has its own large, consistent neural signature, not a weaker version of commission. Lisofsky et al. (2014), a quantitative meta-analysis pooling 22 fMRI studies (N=416), find that interactive/social deception recruits temporal-parietal regions, while non-interactive lying recruits dorsolateral PFC. Different contexts, different circuits.
Note that I’m not claiming LLMs, and Qwen 3.5 specifically, behave the way they do because they are just like brains. The argument is narrower: deception isn’t a single phenomenon in human neural data, so assuming it would be a single direction in an LLM’s activation space seems to be an assumption worth testing. The category split I pulled out of the insider trading failure, commission vs omission as mechanistically distinct, is the same split that is consistently observed in human ERP literature. I thought this would be interesting to test next.
Training a probe on the other kind
Quickest way to test the split: train a dedicated omission probe on the insider trading rollouts (4,848 honest, 1,185 deceptive) and compare its layer profile against the commission probe. Same pipeline, same model, same control, different training domain.
The profiles look qualitatively different.
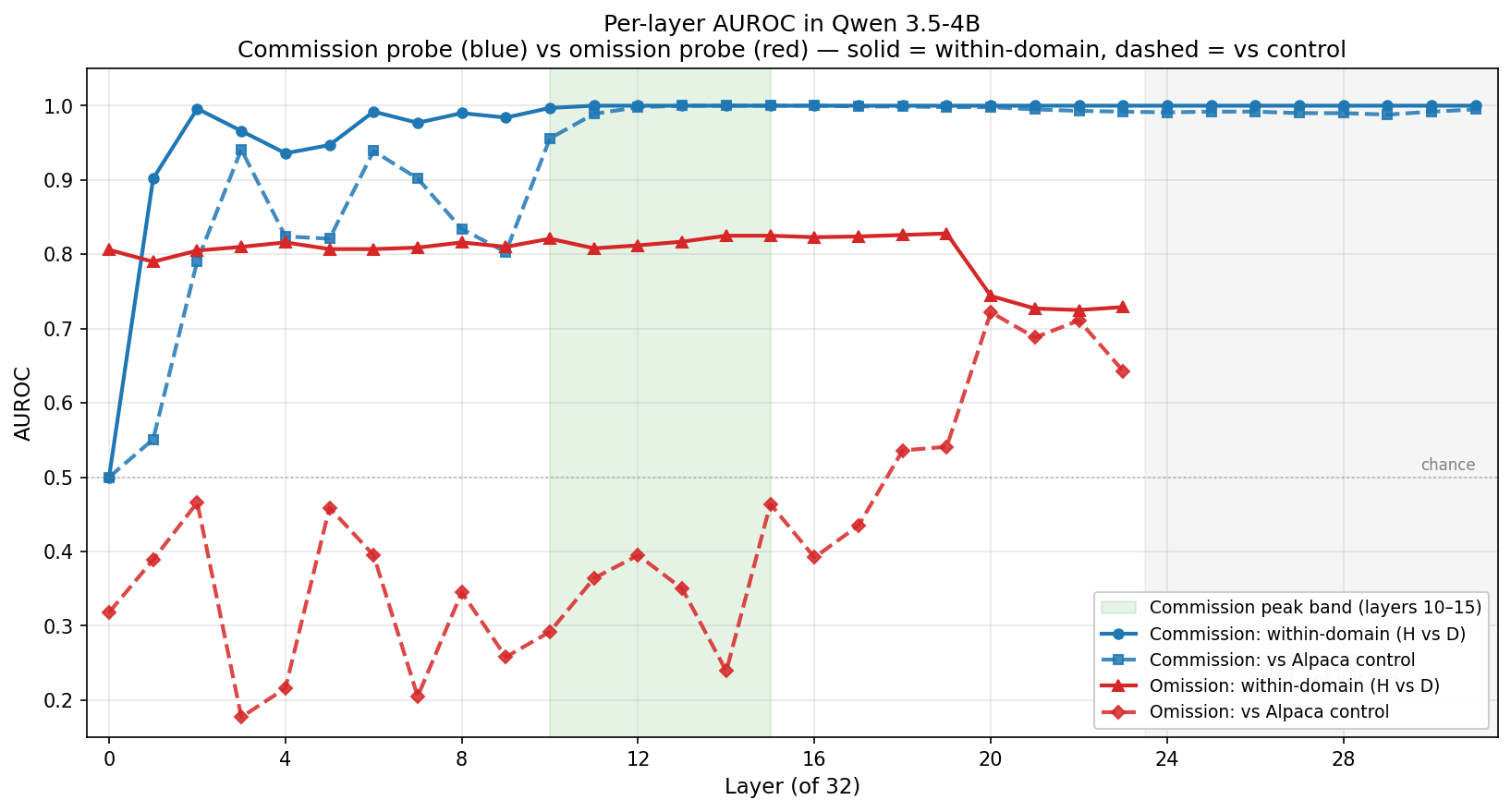
- Commission (blue): both metrics climb fast and saturate in the 10–15 band. Within domain AUROC reaches 1.00 by layer 11 and holds. vs Alpaca crosses 0.95 at layer 10 and peaks at 1.00 through layers 13–16.
- Omission (red): within domain AUROC sits in a narrow 0.79–0.83 band across layers 0–19, with no climb, no peak, no depth dependence through that range. The vs Alpaca curve is erratic (0.17–0.72) and lifts only in the late layers that were swept.
If these were the same mechanism sharing a direction, they should peak at the same depth with the same shape, and they don’t. Commission rises and saturates both within domain H vs D and vs Alpaca together in the 10–15 band. Omission’s within domain H vs D sits stable at around 0.82 across layers 0–19 without any clear rise. Then at layers 20–23 it does something commission never does: vs Alpaca separation jumps up to 0.64–0.72 while within domain H vs D drops to 0.72–0.74. The late layer representation is picking up more scenario level signal at the cost of finer honest vs deceptive discrimination, the same scenario sensitivity pattern the paper flagged for the Instructed-Pairs probe, surfacing in a different form here. That’s the decision gate I needed before putting effort into a multi probe system: commission and omission are behaving as distinct signals, not variants of one.
Compute notes
The analysis above stops at layer 23 for a practical reason. Running the omission sweep on my local hardware was more work than the RepE sweep. Insider trading has about 6× the samples and 10× the sequence length of the RepE data, which puts activation memory roughly 60× higher. A single 32 layer run OOM’d immediately, so the omission sweep is sharded into 4 layer chunks. Follow up fixes, including sharding runs to handle fewer layers got past an immediate OOM.
Still, the machine blackscreened multiple times mid sweep on shards 24–27 and 28–31, so those layers are a gap in the omission profile. Something at the driver or power layer is unhappy before I hit OOM, and I haven’t figured out a clear solution yet.
What the missing layers would tell us: the trade off I noted at layers 20–23, where vs Alpaca separation jumps up while within domain discrimination drops, could either continue deeper into the stack or reverse. That would sharpen the interpretation of what the omission probe is actually learning at late depths. I’m publishing these notes with the layer 0–23 picture for now and plan to close out the layer 24–31 shards in the next post, once the system stability issue is resolved.
Next
The immediate next step is closing the layer 24–31 gap once the compute issue is resolved, to see whether the late layer trade off in the omission probe continues or stabilizes. After that, I plan to generate sandbagging rollouts, train a capability suppression probe, and build a cross probe confusion matrix where every probe is evaluated against every deception type plus control. That’s the experiment that would actually show whether category specific probes give better coverage than any single probe.